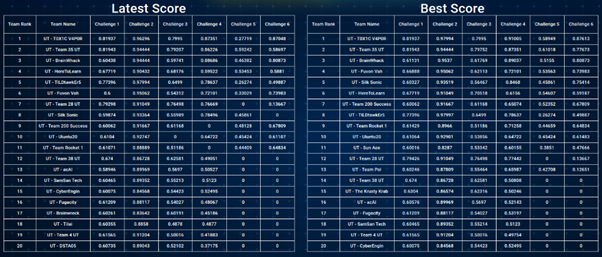
Brainhack 2021 - CV and SC Competition
 31 Jul 2021 - Jeremy See
31 Jul 2021 - Jeremy See
DSTA Brainhack 2021: Object Detection and Speech Classification
Having participated in Brainhack 2020, my team and I decided to come back for the online sequel - COVID edition! This year, we were required to develop robust Object Detection models and Speech Classification to classify the word in a given audio clip. The preliminaries were held over a month, where the top teams were invited to a week-long final.
Fortunately, our team had built a sufficiently robust machine learning pipeline that allowed us to easily enter the finals with our 1st place public leaderboard scores. During the finals, datasets were released every two days with an increasing number of classes and variations in the train/test set. Here’s how we managed to clinch first place:
Object Detection
For the object detection challenge, our team decided to use the Detectron2 framework by Facebook Research. Many bleeding-edge models such as UniverseNet and VariFocalNet were available and easy to deploy using this technology, allowing us to start from pre-trained benchmarks. This allowed us to save a lot of time training with the limited hardware we had available from Google Colab, for this time-constrained competition.
Before starting each stage of the challenge, we had to merge the new datasets into the existing ones. Fortunately, everything was in the COCO format, so it was easy to do so with a simple python script, which allowed me to iteratively append new data with sequential IDs.
For the actual data pipeline, we used Detectron2’s in-built Albumentations library to add augmentations to the train set, including ShiftScaleRotate, RandomBrightnessContrast, JpegCompression, and normalised the data to fit our model input layer. Since we were running the training using Detectron2’s command-line interface with a python configuration file, it was relatively straightforward to iterate and determine which set of configurations gave us the best result. Additionally, it made it much simpler to deploy additional training instances on platforms like Google Colab and AWS EC2.
After the augmentations, the model was trained on the data (with a separate set for validation) for 50 epochs, or until the test accuracy started to plateau, whichever was earlier to avoid overfitting.
For manual tuning, we decided to take a peek at the output of our model, with the bounding boxes overlaid on the image. We realised that there were some edge cases that the model consistently missed, such as a cluster of objects being under-classified as 2-3 instead of 5-6. I tried to add more data from the OpenImagesV6 dataset, but it didn’t improve the results significantly. In the end, I accepted those as edge cases that would be very hard to account for without significant changes to the model, which couldn’t be done in a short period of time. Otherwise, the model was actually doing pretty well!

One takeaway I had from this, was learning how to use AWS to quickly setup and deploy machine learning training. I made a short bash script to install the required dependencies and pull the data from my Google Drive using gdown, then another script to start training the model and automatically upload the trained model .pth files to Google Drive.
Speech Classification
This challenge was a little more tricky. The first few challenges were pretty straightforward; run the audio through a Melspectrogram, then an Image Classification model, and you would get a model with accuracy >90%. A melspectrogram is a spectrogram obtained by taking the Fast Fourier Transform (FFT) of the audio clip, then adding a mel-filter to account for the sensitivity of human hearing to different frequencies. In this way, the model is able to focus on frequencies “important” to human hearing.
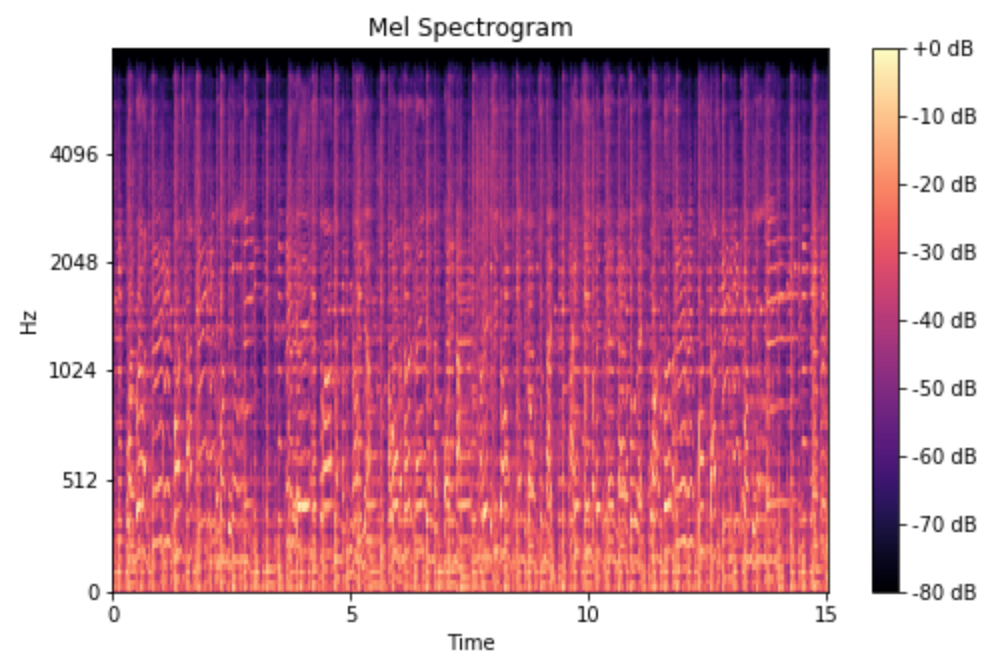
However, in the last challenge, the clips started to sound “robotic”, much like the audio quality from a telephone line in the 90s. We immediately recognised it as a low-pass filter clipping off higher frequencies, similar to how old telephones didn’t have enough bandwidth to encompass higher tones. We added a band-pass filter to cut off frequencies out of the range of human hearing, as well as some of the higher frequencies. This helped us tremendously on the scoreboard, as we were able to pull ahead by several percentage points in test accuracy.
The image augmentations were broadly similar to that of object detection, once the audio was turned into a melspectrogram. The main difference was windowing the audio clip length, to generate a melspectrogram of correct input size to our model, rather than a simple resize.
Conclusion
All in all, Brainhack 2021 was a great experience despite losing the hardware/robotics integration aspect due to COVID-19. My team and I gained a lot of experience in Machine Learning and deployment on web services such as AWS, and really look forward to tackling more, exciting challenges in the future!