Algothon 2021 - ML in Finance
 28 Mar 2021 - Jeremy See
28 Mar 2021 - Jeremy See
Algothon 2021 - ML in Finance
![]()
I participated in Algothon 2021, organised by the Imperial College Algorithmic Trading Society and Aspect Capital. This competition had us creating prediction models, low-latency algorithms, and even a dashboard for financial modelling. It was also my first solo hackathon (as I was based in a different timezone from most participants), which kept the pressure up as I attempted to solve most challenges. My codebase is available here.
Data Cleaning
For this challenge, I went with the simple approach of removing outliers with an adaptive threshold. However, that didn’t turn out well as the grading criteria was using the Mean Squared Error (MSE) of the cleaned vs original “clean” dataset. This meant that removing data points was not an option; I should have normalised detected outliers using a rolling median.
Prediction
This challenge involved predicting the Log-Returns value of provided stocks over a time period of a few years. In essence - picking the correct stocks to buy in the market, and when to sell them - what actual quantitative analysts do at work.
I used Keras’ sequential class to build up a regression model, using all 177 features as the input. However, I found that accuracy was poor in this configuration due to noise from excessive input features. Using Scikit-learn’s Feature Selector to cut down the number of input features would be a first step in improving the accuracy of the model, by removing less correlated features.
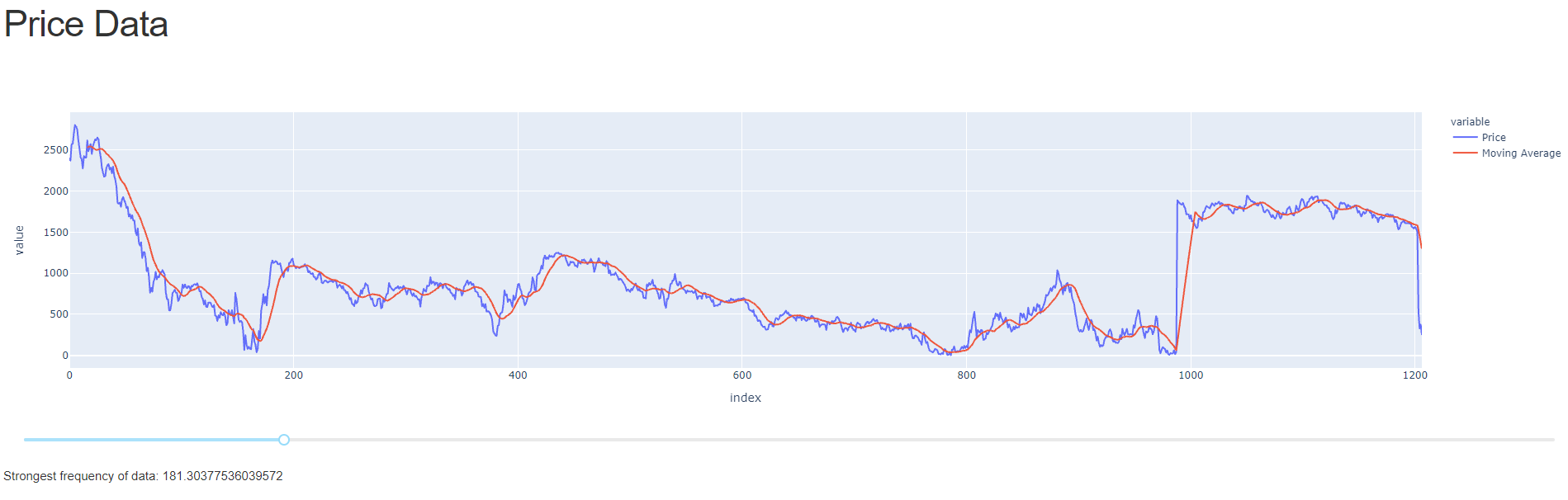
Data Visualisation
The data visualisation task involved showcasing the dataset from the Data Cleaning Challenge. A simple graph was built using Dash Plotly in python, with a simple interactive slider to calculate market momentum using a simple moving average. The demo is available here.
Low Latency Challenge
This challenge involves predicting the rise/fall of a stock price in the next tick. Due to the high-frequency nature of the prediction and underlying data, an accuracy of >50% was requested. Latency was the key here.
The provided training set was a 1826 long time-series data of Log-Returns, which was split into sets of 500 for training purposes.
The algorithm was tested with the dataset provided. After further analysis, it was recognised that the algorithm was not producing consistent results of >50% accuracy. To optimise for speed, a barebones script was used as a Constant Guesser.
The program was written in C++ to minimise latency, with an emphasis on runtime speed and minimal focus on accuracy. The code was tested on an RPI 4 4GB, with a compile time of 11s and a runtime of 9ms (mostly due to the cat write calls).
As an attempt to bring latency down to its minimum, I submitted the program echo 1 to guess my way to victory with a runtime in the microseconds (not including cat) however that didn’t work out as my program failed to run on the organiser’s testbench for an unknown reason.